
最终咱还是陷入了逆向的困境中...
“逐步调试+补全环境”是我惯用的逆向方式,它很符合我个人的喜好,最终的代码既“简单”又“高效”,但不得不承认的是,这种方式实在太耗费时间和精力。
常常会出现这样的情况:为补全一个函数、方法所需要的环境,花了大半天时间,但不一定有结果,过程还极其痛苦,需要独自面对海量、阅读性极差的代码,非常考验个人耐心。
小一点的网站还好,通过这种方式,可能随便捣鼓几下就能得出结果,但对于稍微复杂的网站来说就很困难,如果代码还做了混淆、加密、压缩、分块等处理,那简直难如登天。
这个时候,总会有一股无力感和挫败感朝我袭来。
已经厌倦了,这种低效的方式...
为此,我迫切地想要找到解决问题的办法,以至于我不得不将目光重新转向Webpack:市面上的网站,不敢说99%,起码也有90%是这类打包工具生成的代码。
当然,这里说的Webpack逆向,其实更多的是指对各类打包代码的逆向,后续也会沿用这层含义。
早就听闻逆向Webpack,可以快速达成逆向需求,它无需注重具体的代码细节,只关注如何找到目标方法,以及如何调用。更简单地说,就是找到原本已经实现的功能为我们所用。
乍一看,这种“白嫖”的方式,确实高效。
但因为之前认为Webpack逆向实在过于繁琐,首先要得在海量的代码里找到名为“加载器”的东西,其次总是一大片一大片地复制代码,有的甚至直接下载一堆文件,最后还要“补浏览器环境”,如window、document、navigator、location对象等。
总之,一套操作下来,令初出茅庐的我眼花缭乱,觉得这种方式高深困难,不适合新手,而且也不符合我本人的理念:最终的代码毫无章法,既不精简,也不美观,并且我一直坚信着“只要掌握好心法就能畅通无阻”这样的想法,所以几乎没在这上面花过时间。
关于逆向Webpack,还流传着这样的一个说法,“如果你不会Webpack逆向,你就不能说自己会js逆向”,之前我不太认同,但今天再次审视这句话时,好像确实有那么点道理。
现在绝大多数前端项目都已经实现了工程化,Webpack、Vite、Gulp等就在其中扮演了重要的角色,无论是编译、构建,还是优化、测试,都少不了它们的身影。
鉴于这种情况,不会Webpack逆向确实很影响逆向的效率,甚至是寸步难行,举个极端但更易理解的例子,现在不会Webpack逆向,就如同前端开发不会Vue、JavaWeb不会Spring。
毕竟是关乎效率的问题,不得不学。
近期刚好有逆向推特的需求,且推特所用的打包工具也刚好是Webpack,很适合作为本次的分析目标。
之前在推特下载文件时,使用的从来都是别人的工具,不是说不好用,而是说自己出于学习的目的想研究研究... 起初是打算有使用推特api,但是奈何非常难用,不仅死贵,限制还多,真不如正常请求。
一、原理
首先得提醒,这里说的是webpack打包后的代码如何在浏览器运行的原理,而非Webpack的打包原理。
可以粗浅地概括:webpack将代码拆分到各个文件中,单个文件也称为“模块”,以script标签的形式从服务器加载,加载完成后将代码存储到一个容器中,如下图中的webpackChunk_twitter_responsive_web:
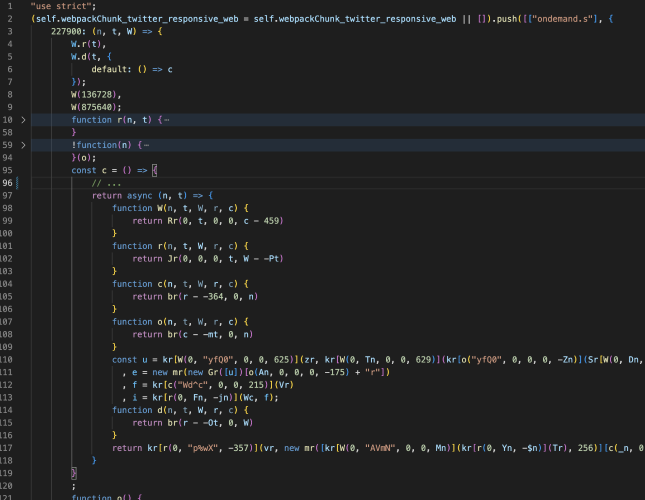
图1-1 Webpack模块文件示例
模块中可包含多个以方法形式存在的子模块,由加载器统一调用。此过程会创建出系统所需要的方法或对象,并保存供后续使用(类似于IoC容器)。
// 加载器的基本格式
var e, a, d, r, n, t, o, l, c, i = {}, s = {};
function b(e) {
// 参数e是子模块id,如上图的227900
// s为保存各模块创建的方法&对象的容器
var a = s[e];
// 以下的代码可以概括为:如果容器存在指定模块的方法、对象,直接返回,否则调用方法进行创建
if (void 0 !== a)
return a.exports;
var d = s[e] = {
id: e,
loaded: !1,
exports: {}
};
process.stdout.write(e + " ");
return i[e].call(d.exports, d, d.exports, b),
d.loaded = !0,
d.exports
}
二、目标定位
推文接口分有两种类型,一种是所有人开放的接口;另一种是需要认证的接口,除了登录凭证外,还需要动态校验参数“client-transaction-id”,只有两个一同向服务器请求时,才能成功返回数据。
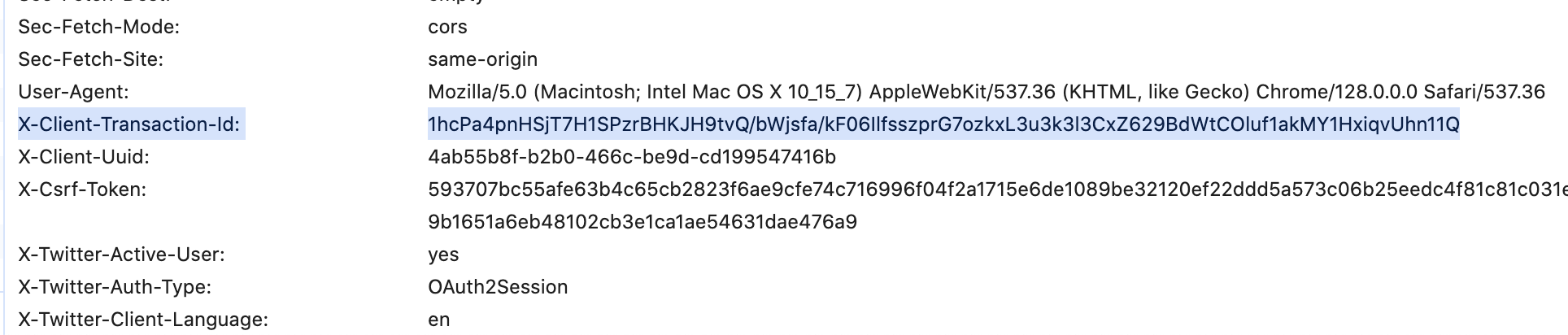
图2-1 client-transaction-id
很明显,它是逆向成功与否的关键所在。
也比较幸运,将其当做关键字检索时,很快就找到了相关代码。
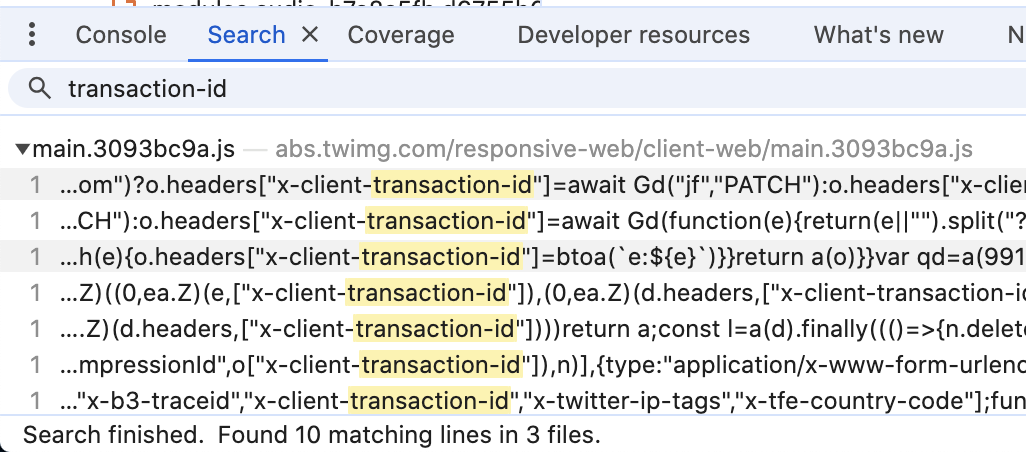
图2-2 检索client-transaction-id位置

图2-3 生成client-transaction-id 1
try {
d.host.includes("jf.x.com") ? o.headers["x-client-transaction-id"] = await Gd("jf", "PATCH") : o.headers["x-client-transaction-id"] = await Gd(function(e) {
return (e || "").split("?")[0].trim()
}(a), e)
} catch (e) {
o.headers["x-client-transaction-id"] = btoa(`e:${e}`)
}
在该位置打上断点,进入方法体,发现其返回了o方法的调用。
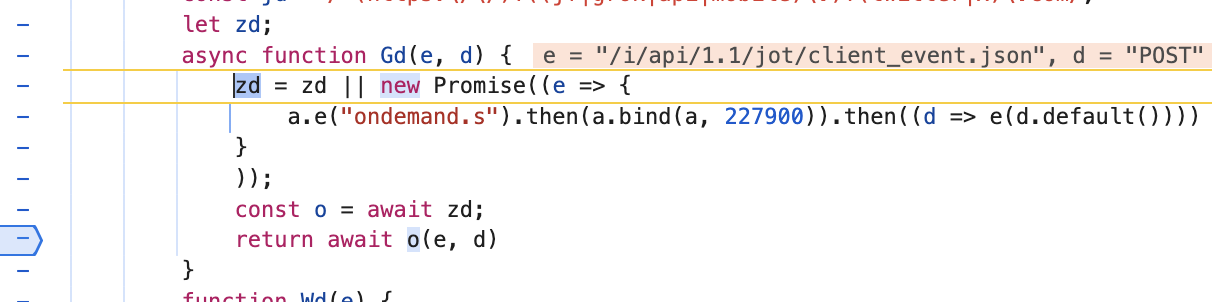
图2-4 生成client-transaction-id 2
继续下一步调试,此时已经跳转到另一个文件ondemand.s.xxx.js。
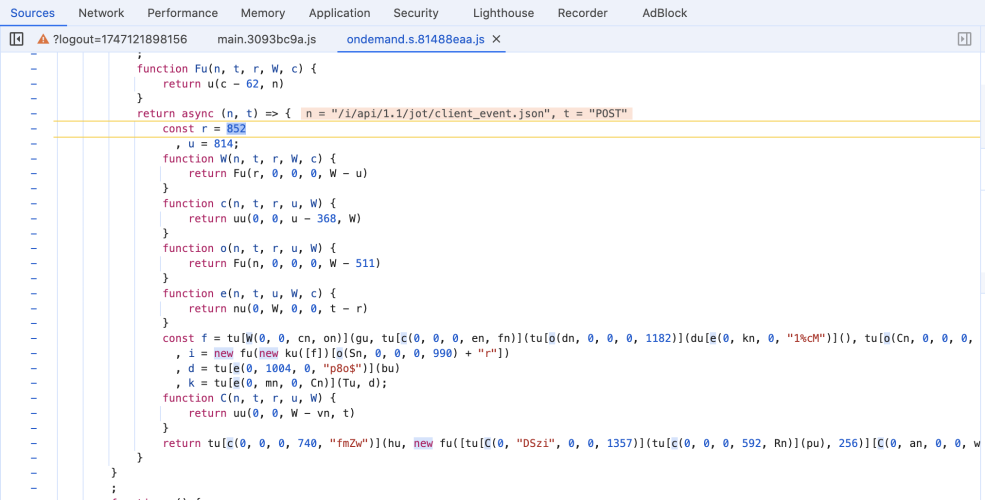
图2-5 生成client-transaction-id 3
看起来,这就是目标方法。因此,要“千方百计”地将其找出来为我们所用,当成功调用该方法时,表示逆向成功。
其实这正是开头图1-1里的文件,尽管形式有所不同,但确实是功能相同的一套代码。在图1-1中,227900模块把c方法作为default方法的返回值,结合图2-4,Promise同样返回了default方法的调用,因此,不难猜测,图2-4中的o方法,正是图1-1中的c。
三、加载器
定位到目标代码后,紧接着需要找到代码加载器,等会需要使用该加载器调用模块方法。
加载器一般在当前HTML文档中。
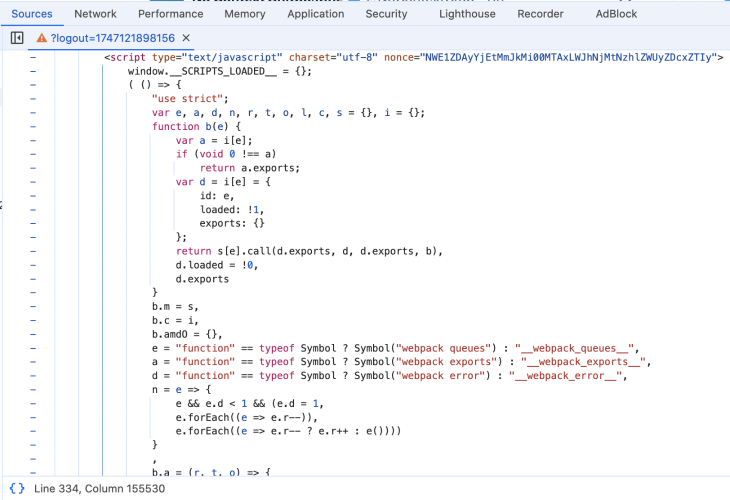
图3-1 加载器 1
将这一坨原封不动地复制下来,保存到本地文件中。
加载器一般都会有exports、loaded、call等关键字,多看几次就熟悉
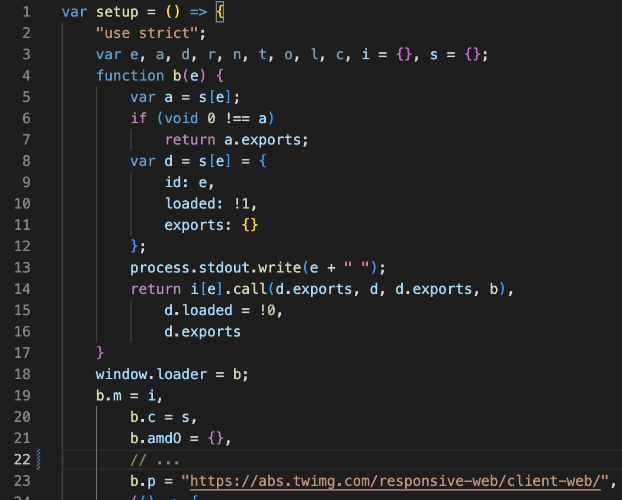
图3-2 加载器 2
将加载器暴露到外包以供调用window.loader = b;。
四、模块文件
将当前页面所依赖的js文件全部拷贝到本地,可以选择“存储当前页面”,这样一来,浏览器会自动把包括js在内的所有文件下载,但由于ondemand.s.xxx.js是动态加载的文件,所以不会包含在内,需要单独下载。
(为了其中一个功能,把所有的代码都跑一遍,有种“火力覆盖”的感觉...)
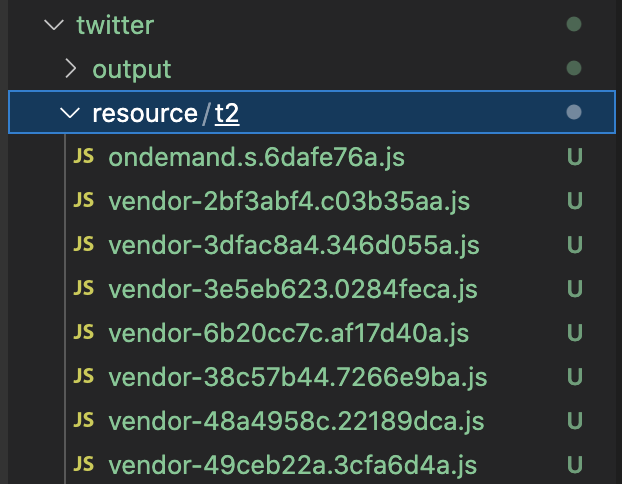
图4-1 模块文件
五、补环境
通常情况下,刚开始在本地运行时会伴随各种各样的错误,毕竟node虽然同为js运行环境,但也与浏览器环境存在较大差异,如node环境没有DOM和BOM,而当模块文件中读取、调用这些不存在的属性和api时,就会报错。
因此,作为替代,在node环境中要显示声明一些同名的对象、属性、方法,以保证程序能正常运行,业界把这一步称为“补环境”。
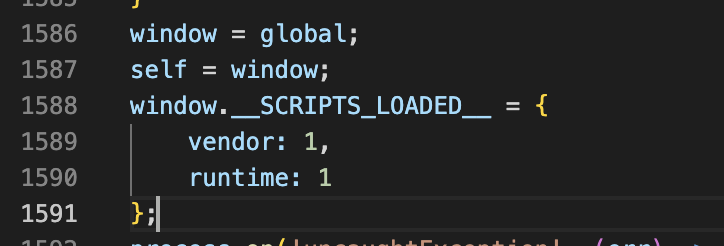
图5-1 声明window、self对象
1、env.js
为使代码看起来整洁,将大部分补环境声明统一定义在env.js文件中,通过require('./env.js')加载。
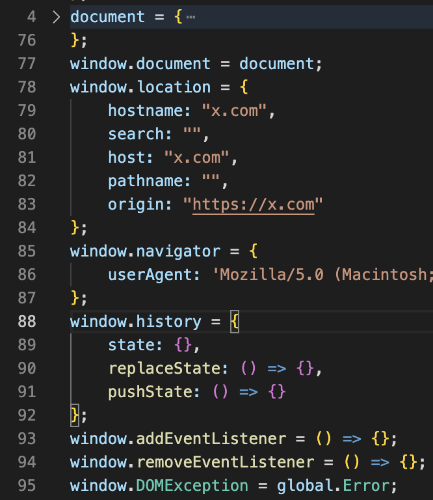
图5-2 声明document、location等对象
总之就是看到缺什么补什么,直到没有影响运行的错误为止。
2、loadResources
相当于浏览器通过script标签从服务器加载文件。
function loadResources(basePath) {
console.log(loadResources.name);
const fileNames = fs.readdirSync(basePath).filter(item => item.endsWith(".js")).map(item => basePath + '/' + item);
for (const item of fileNames) {
console.log('加载:' + item);
require(item);
}
}
3、run
定义程序执行入口方法。
function run() {
require('./env'); // 补环境
loadResources(path.join(__dirname, './resource/t2'));
setup(); // 加载器
const m227900 = window.loader(227900); // 加载指定模块
console.log("\n");
console.log(m227900);
}
run();
4、运行run方法
使用node运行app-webpack-1.js后,可以看到m227900模块已经被输出到控制台中。
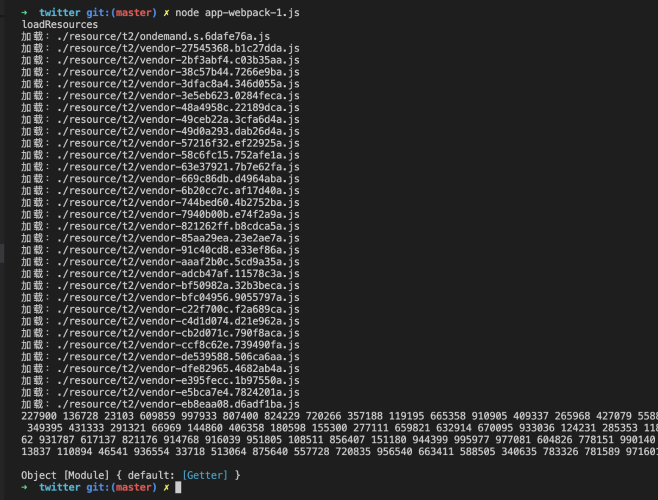
图5-3 app-webpack-1.js执行结果
六、再补环境
在这个步骤中,将使用前面逆向得到的m227900模块尝试生成client-transaction-id。
const fn = m227900.default();
const transactionId = await fn("/i/api/graphql/xd_EMdYvB9hfZsZ6Idri0w/TweetDetail", "GET");
console.log("transactionId: %s", transactionId);
不过,运行时却得到以下结果。
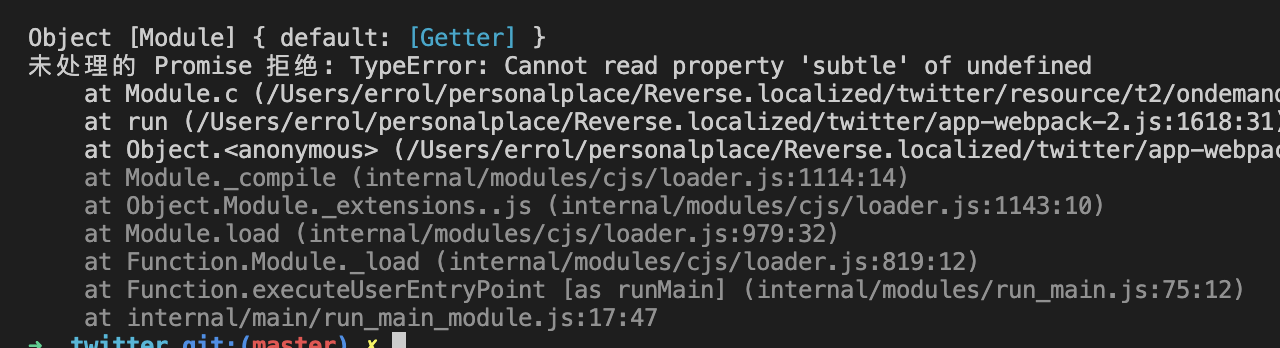
图6-1 TypeError: Cannot read property 'subtle' of undefined
这是由于方法内部使用了window.crypto.subtle属性(目前crypto为undefined),光看名字就知道是与加密相关的api,所以要继续补环境。
1、subtle
经调试可知(还请由读者自己完成),最终fn内部会调用window.crypto.subtle.digest来生成加密数据。
为env.js文件中的window对象新增crypto属性。
// encode是node环境中与window.crypto.subtle.digest相当的简单实现
const { encode } = require("./utils/crypto");
const { atob, btoa } = require('./utils/transaction_id_generator');
window.crypto = {
subtle: {
digest: encode
}
};
// 同理,还有`window.atob`和·`window.atob`
window.atob = atob;
window.btoa = btoa;
2、tsv&d
此外,算法法中还有与HTML页面交互的部分代码,具体是:请求页面时,服务器会动态生成一组数据插入其中,随后前端通过调用document.querySelectorAll来获取数据,直接或间接作为生成client-transaction-id算法的参数。
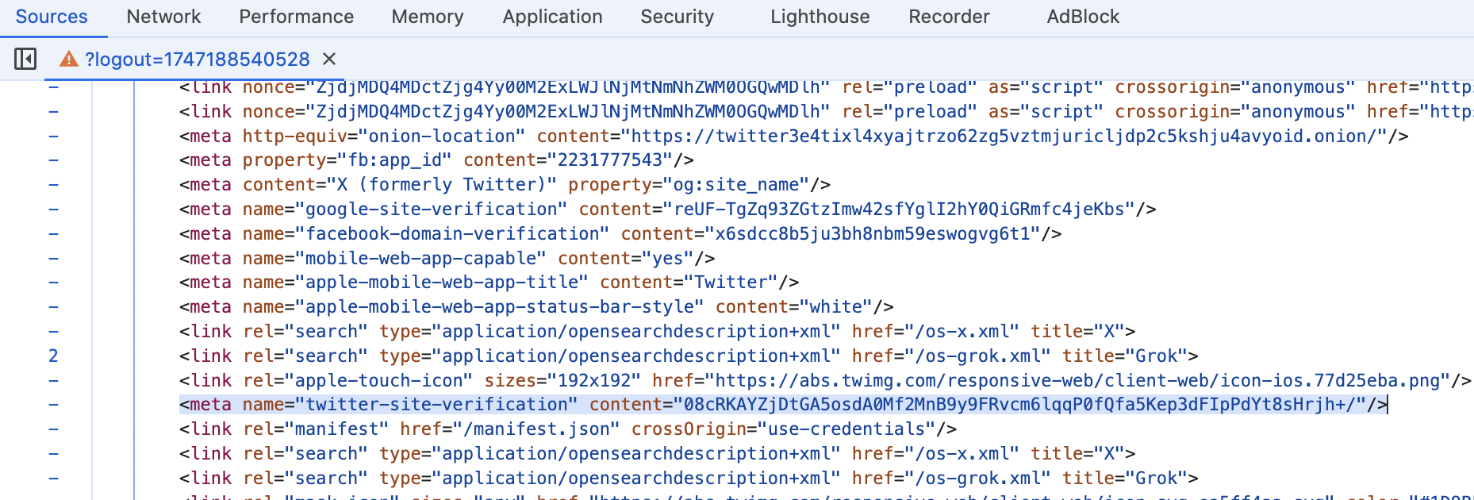
图6-2 meta标签中的twitter-site-verification参数

图6-3 svg标签中的d参数
因此,还需要将这些数据提取出来给算法使用,同时也意味着需要额外发起一次html页面请求。
// 在run方法顶部新增如下代码;
// 主要是请求https://x.com/home,并解析其中的参数;
async function run() {
const rootDir = process.argv[1].replace(/\/[^\/]+$/, '');;
const config = getConfig(rootDir);
config.rootDir = rootDir;
const proxyAgent = new HttpsProxyAgent("http://127.0.0.1:7897");
// 获取推特页面,以解析tsv和d参数
const html = await fetchFile("https://x.com/home", {
headers: {
'user-agent': config.user_agent,
},
agent: proxyAgent
});
const htmlParsed = htmlParser(html, { attributes: ['d', 'tsv'] });
window.tsv = htmlParsed.tsv;
window.d = htmlParsed.d;
console.log(htmlParsed);
// ...
}
3、改造document.querySelectorAll
模拟返回dom节点。
document = {
// ...
querySelectorAll: (selector) => {
// console.log(selector);
// 返回tsv;模拟meta对象
const nodes = [];
if (selector === '[name^=tw]') {
const meta = { content: window.tsv };
const getAttribute = key => meta[key];
meta['getAttribute'] = getAttribute;
nodes.push(meta);
return nodes;
}
// 不同的demand.s.xxx.js文件selector不一样,但每个文件的selector是固定不变的,使用console.log(selector)打印一次即可;
if (selector === '.r-3p73i0') {
const d = window.d;
for (const item of d) {
const svg = {
tagName: 'svg',
childNodes: [
{
childNodes: [
null,
{ getAttribute: () => item },
]
}
]
};
nodes.push(svg);
}
}
return nodes;
}
// ...
}
4、生成transaction-id
在经过漫长的补环境流程后,终于看到了点成果。

图6-4 node app-webpack-3.js的执行结果
七、请求推文
请先在config.txt文件中配置自己cookie后再往下,cookie为刚需。
1、getTweet
定义请求推文方法,看似参数非常多,但其实只要修改一个,其他都是固定值,可以直接拷贝。
但请务必要确保请求推文和生成transaction-id的参数保持一致,即请求url和请求方法。
async function getTweet(params) {
const { transactionId, config, proxyAgent, tweetId } = params;
// const tweetId = config.tweet_url.match(/.*?\/(\d+)/)[1];
const ct0 = config.cookie.match(/ct0=(\w*);?/)[1];
const query = {
"variables": `{"focalTweetId":"${tweetId}","with_rux_injections":false,"rankingMode":"Relevance","includePromotedContent":true,"withCommunity":true,"withQuickPromoteEligibilityTweetFields":true,"withBirdwatchNotes":true,"withVoice":true}`,
"features": "...",
"fieldToggles": "..."
};
const query1 = querystring.stringify(query);
return await fetchJson(`https://x.com/i/api/graphql/xd_EMdYvB9hfZsZ6Idri0w/TweetDetail?${query1}`, {
"headers": {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"authorization": "Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA",
"content-type": "application/json",
"x-client-transaction-id": transactionId,
"x-csrf-token": ct0,
"x-twitter-active-user": "yes",
"x-twitter-auth-type": "OAuth2Session",
"x-twitter-client-language": "en",
"cookie": config.cookie,
"user-agent": config.user_agent
},
"body": null,
"method": "GET",
"agent": proxyAgent
});
}
2、再次执行run方法
在run方法下方加入如下代码后运行node app-webpack.js 。
async function run() {
// ...
const transactionId = await fn("/i/api/graphql/xd_EMdYvB9hfZsZ6Idri0w/TweetDetail", "GET");
console.log("transactionId: %s", transactionId);
const tweetId = config.tweet_url.match(/.*?\/(\d+)/)[1];
console.log("tweetId: %s", tweetId);
const respData = await getTweet({ transactionId, tweetId, proxyAgent, config });
if (respData) {
console.log("获取成功");
const jsonStr = JSON.stringify(respData);
console.log(jsonStr);
fs.writeFileSync(path.resolve(__dirname, `./output/${tweetId}-${Date.now()}.json`), jsonStr);
}
else {
console.logg("获取失败");
}
}
最终成功获取到推文数据:

图6-5 https://x.com/mitadms/status/1922097619347636323推文
响应数据已保存至本地文件(/output/{tweet_id}.json),找到需要的资源链接后,可直接在浏览器打开,但仍需要梯子,懂的都懂。
如这里找到的其中一个视频链接,并于浏览器搜索栏中打开,然后就看到了我们的米塔。
不过,这其实是一条公开的推文,当然,也可以试着去找一条需要登录的敏感推文(涉及黄暴),同样能获取成功,在此不过多展示。
八、结语
如同传闻中的那样,Webpack逆向可以快速完成逆向需求,除了补环境以外,几乎不需要写代码,比我先前逐步调试的方式好了不止一星半点,想到以后能减少那无聊乏味的出栈入栈操作,我就忍不住轻哼起来。
这个过程主要在于“找”和“调”,即“找到目标方法,并调用”... 果真就是“白嫖一时爽,一直白嫖一直爽”。
速度才是王道,其他都是虚话。
到现在为止,如果还有读者还对Webpack逆向的效率有疑惑的话,那么接下来我贴出一个基于油猴脚本的transaction-id逆向版本,它简直把“白嫖”发挥到了极致。
// ==UserScript==
// @name transaction-id逆向
// @namespace http://tampermonkey.net/
// @version v0.0.1
// @description try to take over the world!
// @author [email protected]
// @match https://x.com/*
// @icon https://www.google.com/s2/favicons?sz=64&domain=x.com
// @grant none
// @run-at document-start
// ==/UserScript==
(function() {
'use strict';
var hacked = false;
const svgs = [];
let loader, zd;
function getZd() {
let m227900;
if (!loader || !(m227900 = loader.c['227900']) || svgs.length !== 4) {
throw new Error('环境参数错误');
}
document.body.append(...svgs);
const fn = m227900.exports.default();
return fn;
}
async function Gd(e, d) {
zd = zd || getZd();
const o = await zd;
return await o(e, d);
}
window.Gd = Gd;
const _call = Function.prototype.call;
// 拦截call方法,并获取到加载器
Function.prototype.call = function(_this, ...args) {
if (!hacked && args.length === 3 && typeof args[2] === 'function' && args[2].b === document.baseURI) {
hacked = true;
Function.prototype.call = _call;
loader = args[2];
}
return _call.apply(this, [_this, ...args]);
}
const _rc = Node.prototype.removeChild;
// 因为demand.s.xxx.js模块初始化完成后,会将svg从文档中删除,所以要在这里拦截,在调用getZd()的时候会使用到,否则会出现找不到节点的问题
Node.prototype.removeChild = function(node) {
if (node.tagName === 'svg' && node.id.startsWith('loading-x-anim')) {
svgs.push(node);
if (svgs.length === 4) {
Node.prototype.removeChild = _rc;
}
}
return _rc.call(this, node);
}
})();
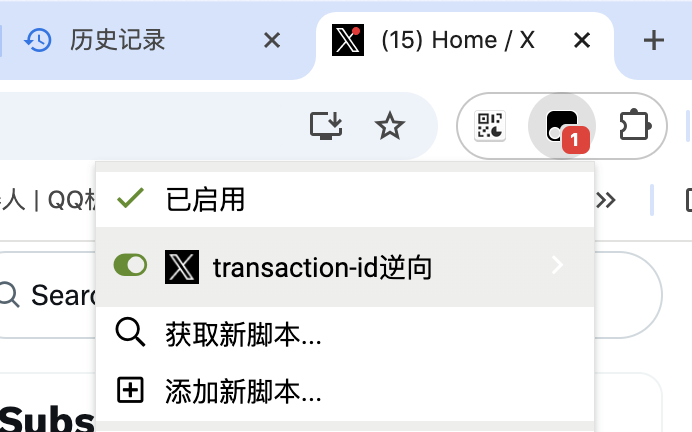
图7-1 启用当前脚本
随后在浏览器控制台调用挂载在window对象的Gd方法,一样能生成transaction-id。
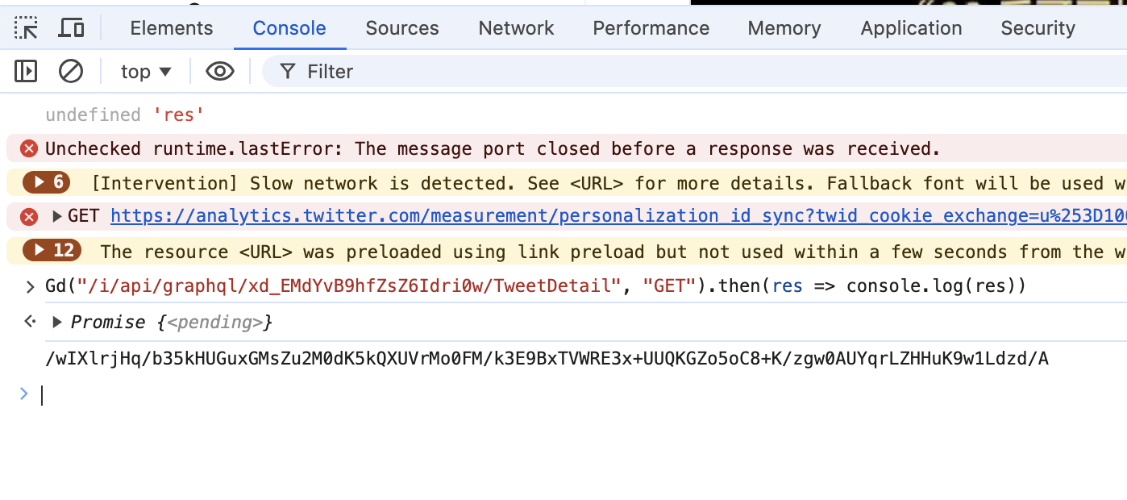
图7-2 Gd执行结果
虽然只有短短的几十行代码,但也能够达到相同的目的,这就是Webpack逆向的厉害之处,它大幅减少了逆向的成本。
当然,也并不是说只要Webpack逆向而把逐步调试抛弃,这二者本该为一体,或者说逆向本身就是一个调试的过程,它们的关系更像语言和框架,只有二者结合起来,才能发挥出最大功效。
为此,本文提供了一个非逆向webpack的实现,就在本文代码的同级目录下(/root/app.js),算法几乎都是纯逐步调试+手动复现,感兴趣的读者可以看看,只要稍作对比就知道,在效率和难度方面,二者的差距有多大。
真香警告。
我承认以前是我说话大声了点,现在已经无法自拔地喜欢上Webpack逆向了,因为它实在太高效,更何况它还简单。
你知道的,我早就是一名Webpack逆向的推崇者了,一起学...?
本文代码。